Apprendimento contrastivo: una strategia promettente contro il malware
 Redazione SecurityOpenLab
Redazione SecurityOpenLab CrowdStrike ha sfruttato l’apprendimento contrastivo per migliorare la detection dei malware PE, combinando diverse tecniche di apprendimento e reti neurali convoluzionali.




Uno dei temi attualmente più rilevanti in ambito cyber è la necessità di riconoscere e di bloccare a velocità macchina le minacce in continua evoluzione. Per farlo, quasi tutti i vendor confidano nell’uso dell’intelligenza artificiale, anche se addestrare un modello di AI affinché svolga efficacemente questo compito non è per nulla semplice, considerato (fra le altre cose) che la creazione di funzioni innovative di malware detection è un processo complesso e dispendioso sia in termini di tempo che di risorse.
Una lettura interessante per farsi un’idea di quello che accade dietro alle quinte di una funzione di rilevamento malware è un recente paper in cui CrowdStrike descrive come i propri data scientist stiano lavorando al miglioramento della detection di malware PE (Portable Executable) facendo uso di tecniche di apprendimento contrastivo. Il lavoro dimostra come un approccio di questo tipo possa effettivamente incrementare l'efficacia dell'apprendimento automatico nella cybersecurity, con risultati apprezzabili.
Il documento diffuso dal vendor è molto tecnico; in questa sede ne presentiamo una sintesi semplificata per dare modo ai lettori di comprendere la dinamica alla base del lavoro svolto. Per i dettagli tecnici rimandiamo al post sul blog ufficiale.
Che cos'è l'apprendimento contrastivo
L'apprendimento contrastivo è una tecnica impiegata nel machine learning per insegnare ai modelli a distinguere tra elementi simili e dissimili. L'idea di base è quella di avvicinare, nel cosiddetto spazio di embedding, le coppie di dati simili (coppie positive) e di allontanare quelle di informazioni dissimili (coppie negative). Nell’esempio del riconoscimento di immagini, si possono creare diverse versioni modificate della stessa immagine (ruotata, ritagliata, con colori differenti, eccetera) per addestrare il modello a riconoscere tali versioni come correlate e a distinguerle da immagini completamente diverse.
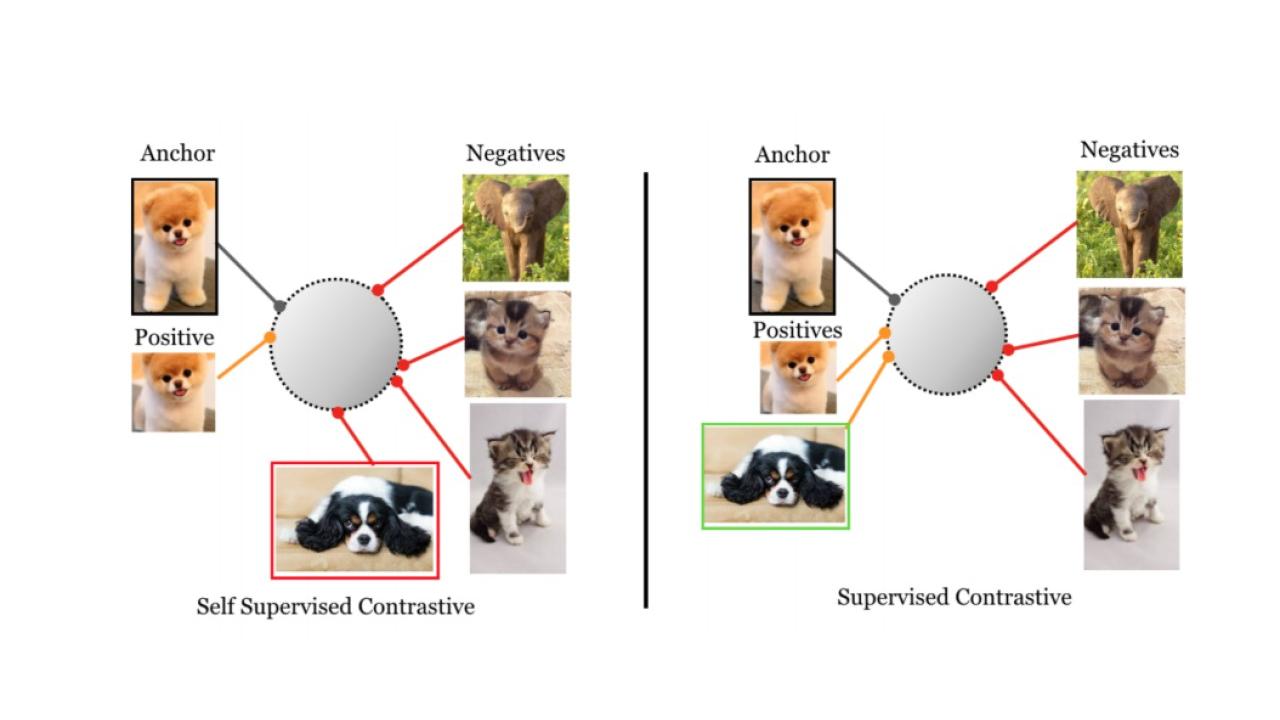 Rappresentazione schematica della differenza fra i modelli citati nell’articolo. Crediti immagine
Rappresentazione schematica della differenza fra i modelli citati nell’articolo. Crediti immagine
Un’applicazione diffusa della tecnica di apprendimento contrastivo è il SimCLR (Simple Contrastive Learning) sviluppata da Google Research (ex Google Brain), che torna utile nell’analisi dei malware perché consente al modello di apprendere informazioni da usare successivamente per classificare o riconoscere oggetti, anche in assenza di etichette.
Apprendimento contrastivo supervisionato
Nel suo paper, CrowdStrike evidenzia un problema del framework SimCLR: per ottenere risultati ottimali, necessita di utilizzare batch di dati di grandi dimensioni, che richiedono ingenti risorse, aumentando il rischio di dover analizzare più campioni della stessa classe (cosa che mette in difficoltà l'algoritmo) e rallentano le operazioni.
Per ovviare a questi limiti i data scientist di CrowdStrike hanno fatto ricorso a due elementi. Il primo è l'apprendimento contrastivo supervisionato (SupCon, acronimo di Supervised Contrastive Learning). Semplificando al massimo, mentre SimCLR sfrutta perdite contrastive per avvicinare nello spazio di embedding un campione àncora (anchor) e un campione positivo (la versione dell'anchor, ruotata, ritagliata, zoomata o altro), allontanandoli da molteplici campioni negativi, SupCon fa uso di più campioni positivi appartenenti alla stessa classe dell'àncora, permettendo così al modello di totalizzare prestazioni superiori a quelle dei modelli tradizionali.
Secondo elemento è la funzione di perdita detta Focal Loss sviluppata da Facebook AI Research per il rilevamento di oggetti, che è particolarmente efficace in scenari di classificazione con classi sbilanciate, ossia quando le classi di interesse (per esempio oggetti specifici all'interno di un'immagine) sono molto meno rappresentate rispetto alle classi non rilevanti (come lo sfondo, nell’esempio dell'immagine). Durante l'addestramento del modello, Focal Loss assegna un peso maggiore agli elementi difficili o rari, riducendo l'influenza degli elementi facili o comuni. Così facendo consente al modello di concentrarsi maggiormente sulle informazioni che altrimenti verrebbero trascurate, migliorando le prestazioni complessive nella classificazione di classi minoritarie.
Per generare uno spazio vettoriale e focalizzarsi sui campioni più difficili da classificare, i ricercatori di CrowdStrike hanno sviluppato una funzione di perdita ibrida, che calcola la perdita sia per la funzione SupCon che per quella Focal Loss, ponderandole con un parametro definito dall'utente.
L’analisi dei file PE con reti neurali convoluzionali
L’ultimo ingrediente che manca per comprendere il lavoro di CrowdStrike riguarda l’uso di un'architettura ispirata al modello convoluzionale MalConv2, che in questo caso consiste in tre componenti: embedding layer, convolutional layer e projection layers. Embedding Layer trasforma i byte grezzi del file da analizzare in vettori numerici , così da convertire i dati binari in una forma che la rete neurale possa facilmente elaborare. I dati così ottenuti passano per il Convolutional Layer, che applica filtri utili per rilevare pattern o caratteristiche specifiche all'interno della sequenza di byte, così da consentire l’individuazione di strutture o di sequenze malevole. Infine, i dati elaborati vengono passati attraverso Projection Layers che preparano l'output finale per la classificazione, determinando se il file sia dannoso o meno. Questa combinazione di strati consente a MalConv2 di analizzare efficacemente i file eseguibili e rilevare potenziali minacce malware.
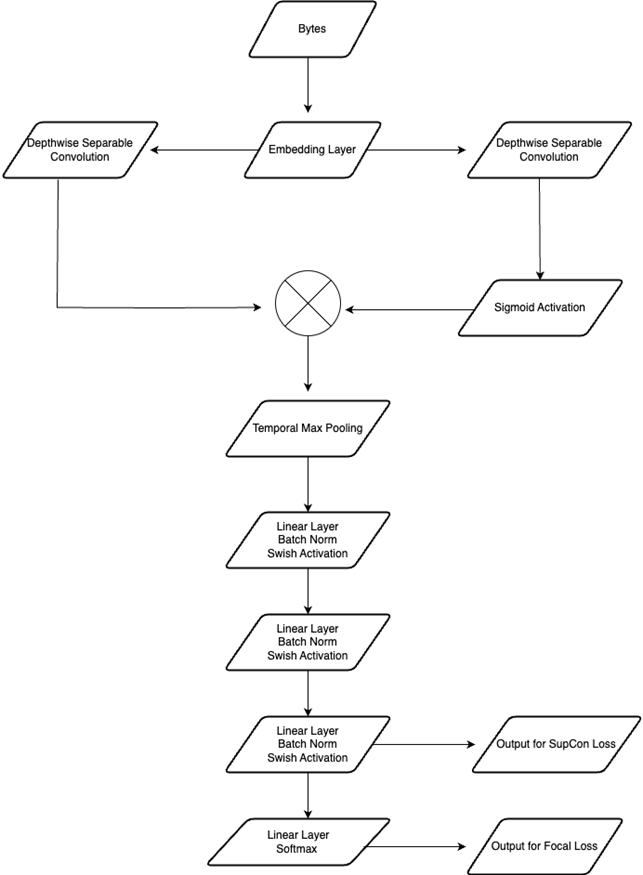 L'architettura del modello, schematizzata
L'architettura del modello, schematizzata
I risultati ottenuti
Il modello è stato addestrato con un set di dati di circa 15,5 milioni di campioni contenenti 500 diverse famiglie di malware. Il numero di campioni per famiglia variava da un minimo di 655 a un massimo di 2 milioni. Per la visualizzazione è stato scelto un sottoinsieme di dieci famiglie di malware, suddivise in cinque famiglie comuni (oltre 300.000 campioni ciascuna) e cinque meno comuni (circa 10.000 campioni ciascuna).
L'applicazione della funzione di perdita Focal Loss ha consentito di tenere ben separate le famiglie di malware, anche in presenza di set di dati ridotti. La capacità di manipolare lo spazio di embedding mediante l'aggiunta di etichette ha permesso di raggruppare i campioni in base al tipo di minaccia (worm, trojan, mineware, ransomware), oltre che in base alla famiglia di malware.
Il modello è stato addestrato applicando l’algoritmo SupCon sia alla famiglia di malware che al tipo di minaccia e calcolando la media tra i due, con una dimostrata efficacia nei risultati. La flessibilità data dalla possibilità di spostare i dati in base a diversi criteri ha permesso di raggruppare i file in base a criteri specifici e di conseguenza identificare nuove minacce. La funzione di perdita ibrida sviluppata da CrowdStrike ha dimostrato di migliorare i risultati dell'apprendimento automatico supervisionato contro il malware PE.
Tutto questo per dire che la tecnica implementata da CrowdStrike si prospetta come un ottimo candidato per l'apprendimento auto-supervisionato sui file PE, sfruttando la grande quantità di campioni non etichettati disponibili.
 Rimani sempre aggiornato, seguici su Google News!
Seguici
Rimani sempre aggiornato, seguici su Google News!
Seguici
Notizie correlate











Speciali Tutti gli speciali
Calendario Tutto
Ultime notizie Tutto
Greenbone porta in Italia il vulnerability management 100% europeo
20-03-2026
Netskope One AI Security: governance e visibilità nell'era agentiva
20-03-2026
Oltre il perimetro: WatchGuard punta su Zero Trust e Open MDR
20-03-2026
AI agentica: memoria, permessi e skill diventano vettori di attacco
20-03-2026
G11 Media Networks
SecurityOpenLab e' un canale di BitCity, testata giornalistica registrata presso il tribunale di Como ,
n. 21/2007 del
11/10/2007- Iscrizione ROC n. 15698
G11 MEDIA S.R.L.
Sede Legale Via NUOVA VALASSINA, 4 22046 MERONE (CO) - P.IVA/C.F.03062910132
Registro imprese di Como n. 03062910132 - REA n. 293834 CAPITALE SOCIALE Euro 30.000 i.v.
