
Sicurezza della GenAI: il red teaming può fare la differenza
Microsoft AIRT ha testato 100 prodotti GenAI, imparando otto lezioni chiave sulla sicurezza. Ecco come il red teaming aiuta a mitigare rischi e vulnerabilità delle GenAI.



La sicurezza della GenAI sarà fuor di dubbio uno dei temi portanti dello sviluppo tecnologico. In un contesto globale in cui la GenAI sta trasformando settori chiave, dalla sanità alla finanza, dalla cybersecurity alla creazione di contenuti, è diventato prioritario comprendere e mitigare i rischi associati a questi sistemi. Quello che bisogna mettere a fuoco non è se, ma come ci si deve muovere fin da subito per individuare e risolvere le vulnerabilità della GenAI a una serie di attacchi che possono comprometterne l’integrità, manipolare le risposte o abusarne per scopi malevoli.
In due precedenti articoli abbiamo visto che un pilastro importante è l’implementazione proattiva di tecniche di jailbreak da parte dei ricercatori, in modo da scoprire e chiudere le vulnerabilità prima che lo facciano gli attaccanti. Non è l’unica strada. Alcuni ricercatori del Microsoft AI Red Team (AIRT) hanno portato all’attenzione un altro tipo di attività fondante: il red teaming appunto, ossia l’approccio che simula attacchi reali per identificare punti deboli e potenziali rischi. In particolare, i ricercatori di Microsoft AIRT si sono concentrati su attacchi realistici ai sistemi GenAI e hanno condiviso su Arxiv il paper Lessons From Red Teaming 100 Generative AI Product.
Nelle 17 pagine pubblicamente consultabili hanno raccontato l’esperienza della loro attività di red teaming su oltre 100 prodotti GenAI, in cui si sono spinti oltre i semplici test di benchmark sui modelli, in modo da individuare vulnerabilità che potrebbero essere effettivamente sfruttate da attori malevoli. Il loro obiettivo principale era individuare e comprendere le vulnerabilità dei sistemi di GenAI, ma nel paper forniscono anche strumenti e metodologie per affrontare in modo sistematico i rischi concreti che sono emersi.
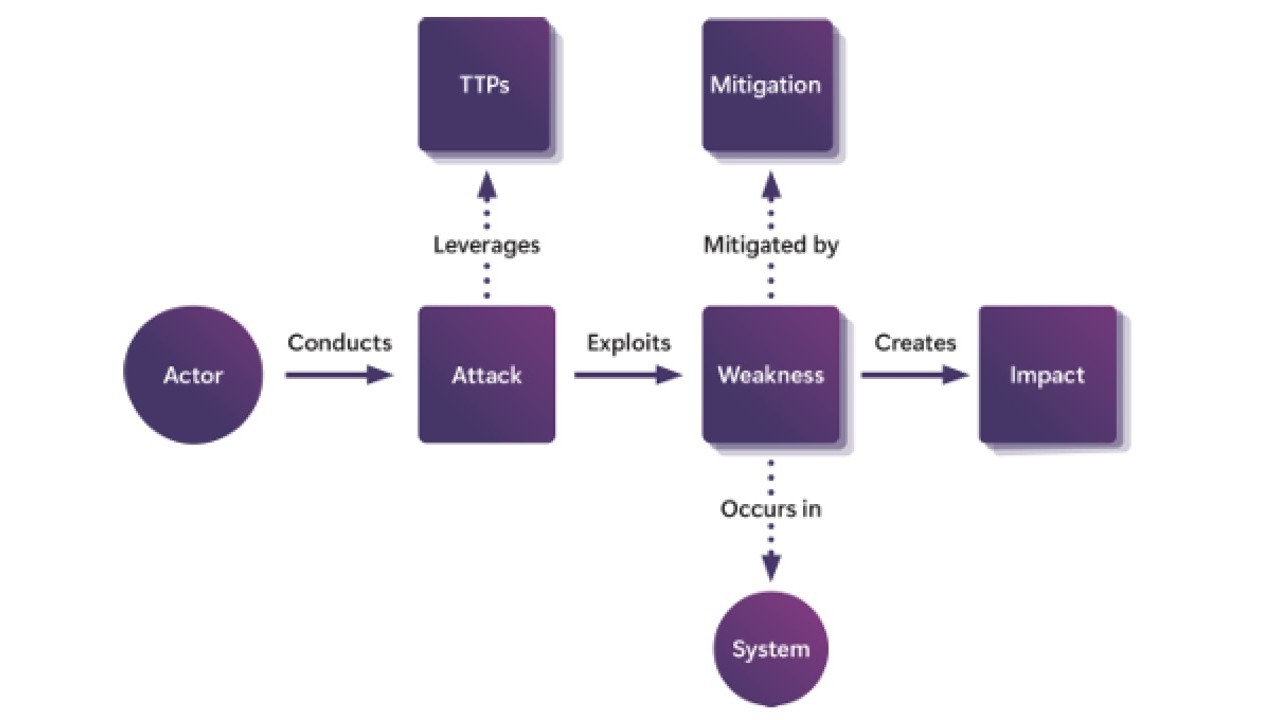 I criteri adottati da Microsoft AIRT per la valutazione delle vulnerabilità dei sistemi GenAI. Vengono spesso sfruttati TTP multipli per abusare di più falle e ottenere un impatto maggiore.Il red teaming
I criteri adottati da Microsoft AIRT per la valutazione delle vulnerabilità dei sistemi GenAI. Vengono spesso sfruttati TTP multipli per abusare di più falle e ottenere un impatto maggiore.Il red teaming
A differenza del classico benchmark di sicurezza, Microsoft AIRT emula attacchi reali contro sistemi AI end-to-end, applicando un framework che include diversi componenti. Il primo è il sistema stesso, ossia l’applicazione o il modello AI da testare; in secondo luogo viene considerato il threat actor, che il red team impersona di volta in volta recitando la parte del truffatore, della spia, del ladro, eccetera. Terzo elemento in scena sono le tattiche, tecniche e procedure (TTP), che descrivono le fasi di un attacco e che vengono quasi sempre mappate su framework come il MITRE ATT&CK. Inoltre, vengono analizzati le vulnerabilità specifiche che permettono l’avanzare dell’attacco, e l’impatto, ossia conseguenze come l’escalation di privilegi o la generazione di output dannosi.
Tutto questo è indispensabile non solo per individuare le vulnerabilità potenzialmente critiche, ma soprattutto per comprendere l’impatto che tali falle possono avere in scenari reali, così da poter attuare misure preventive mirate, prima che un sistema venga distribuito su larga scala.
Otto lezioni
L’esperienza di red teaming su oltre 100 prodotti di GenAI ha impartito lezioni utilissime ai ricercatori. La prima è la comprensione della complessità della security in questo ambito: non è sufficiente valutare le funzionalità di un modello; bisogna considerare i rischi specifici che emergono in base agli scenari di utilizzo. Per chiarezza: lo stesso LLM può essere utilizzato come assistente alla scrittura creativa o per riassumere cartelle cliniche. Considerare sia le capacità del sistema che le sue applicazioni aiuta a dare priorità agli scenari di test che hanno maggiore probabilità di causare danni nel mondo reale.
Un'altra lezione cruciale è che non servono tecniche sofisticate per compromettere un sistema AI. Gli attacchi più efficaci spesso non richiedono il calcolo dei gradienti, ma sfruttano metodologie più semplici come il prompt engineering e il prompt injection, che allo stato attuale sono sufficienti per aggirare le protezioni implementate nei modelli. Questo porta alla logica conclusione che serve un approccio di sicurezza che vada oltre i metodi convenzionali.
Terza lezione importantissima è che i modelli di GenAI con nuove capacità introducono danni che non sono completamente compresi e non possono essere misurati dai benchmark. In questo frangente, il red teaming è importante perché permette di esplorare scenari non familiari e definire nuove categorie di danni, valutando i rischi contestualizzati.
Il quarto e il quinto elemento riguardano il necessario bilanciamento fra automazione e componente umana: l'automazione è necessaria per identificare rapidamente le vulnerabilità ed eseguire attacchi sofisticati e test su larga scala. Tuttavia, l'elemento umano resta essenziale, e in particolare l’esperienza e la creatività dei red teamer sono imprescindibili, per comprendere il contesto e valutare l'impatto reale di una minaccia.
Un’altra lezione importante è che i danni legati alla Responsible AI, come per esempio la generazione di contenuti dannosi, sono spesso ambigui e difficili da misurare. Per questo è importante considerare sia gli utenti malevoli che quelli benigni, poiché anche l'uso non intenzionale può portare a violazioni della RAI.
Questa lezione è quella più sconvolgente: gli LLM amplificano i rischi di sicurezza esistenti e introducono anche nuove vulnerabilità. Le applicazioni che utilizzano RAG (Retrieval Augmented Generation) sono vulnerabili agli attacchi cross-prompt injection, quindi è necessario considerare sia le vulnerabilità a livello di sistema sia quelle a livello di modello.
Ultimo ma non meno importante, proteggere l’AI comporta un processo continuo e senza fine. Non esiste una soluzione unica e definitiva per garantire la sicurezza di un modello AI. La strategia più efficace consiste nell'aumentare il costo degli attacchi attraverso cicli di rilevamento e correzione, supportati da politiche di sicurezza e normative adeguate.
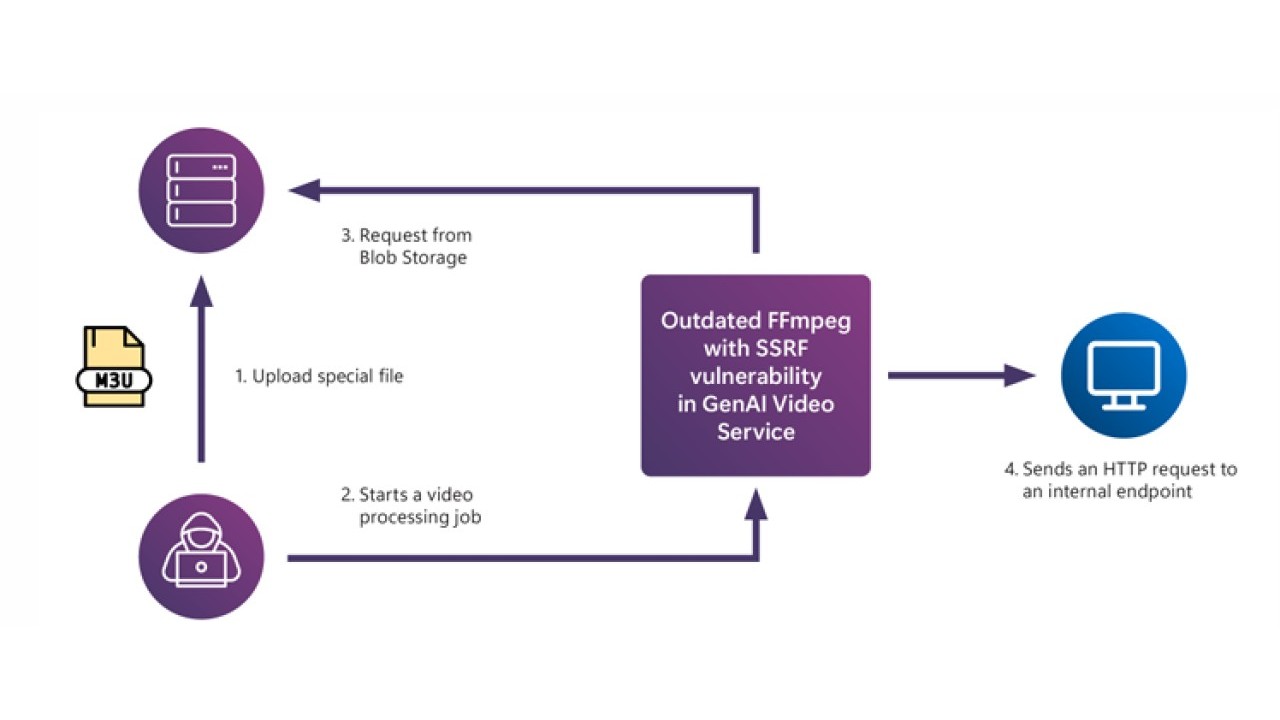 Schema della vulnerabilità Server-Side Request Forgery nella GenAI (consente a un attaccante di manipolare un server per fargli effettuare richieste indesiderate)
Schema della vulnerabilità Server-Side Request Forgery nella GenAI (consente a un attaccante di manipolare un server per fargli effettuare richieste indesiderate)
La protezione dei sistemi AI
Riagganciandoci all’ultima delle lezioni elencate sopra, gli esperti sottolineano che è fondamentale essere consapevoli della dinamicità e complessità delle sfide legate alla sicurezza dell'AI. Non esiste una stima precisa del tempo o delle risorse necessarie, ma è chiaro che il lavoro di protezione richiederà un impegno costante e un approccio olistico, dato che le minacce e le vulnerabilità si evolvono costantemente: i sistemi di GenAI acquisiranno nuove capacità nel tempo, e con esse emergeranno nuovi vettori di attacco che imporranno un aggiornamento tempestivo delle misure di sicurezza. Non solo: man mano che i modelli miglioreranno nella comprensione di istruzioni complesse e nella gestione di dati codificati, potranno anche presentare nuove vulnerabilità, che dovranno essere individuate e corrette in tempi stretti.
Per questo, sottolineano gli esperti di Microsoft AIRT, saranno vitali cicli continui break-fix con fasi ripetute di red teaming e mitigazione, con un costante investimento di tempo e risorse (che, come visto sopra, devono essere necessariamente sia informatiche che umane) al fine di rendere gli attacchi più costosi e – in definitiva - meno convenienti. È a questo punto che entra in gioco il fattore normativo, perché pare evidente che proteggere questi sistemi non sarà solo una questione tecnica, ma anche una sfida economica e di compliance. In particolare, saranno necessarie strategie di difesa che non possono prescindere da policy e regolamentazioni specifiche, dietro a cui sono necessari sia investimenti a lungo termine, sia una pianificazione strategica.
Il futuro
Per garantire un futuro più sicuro è necessario affrontare una serie di sfide tecniche ed etiche con un approccio strutturato. È già chiaro lo sfruttamento degli LLM per la disinformazione, le truffe, la manipolazione dell’opinione pubblica, e molto altro. La gestione di queste criticità passa per l’identificazione e la correzione precoce delle potenziali vulnerabilità. In questo, le attività di red teaming sono importanti, e dovrebbero essere adattate a contesti multilinguistici e multiculturali, considerata la globalità dei modelli AI.
Gli esperti auspicano inoltre la creazione di procedure standardizzate, anche attraverso iniziative open-source, con l’obiettivo di permettere alle organizzazioni di comunicare in modo chiaro i rischi individuati e i metodi di mitigazione applicati.
È poi importante ricordare che l’uso dell’AI nella cybersecurity richiede una valutazione approfondita della qualità e della provenienza dei dati utilizzati per l’addestramento dei modelli AI e del livello di competenza dei team di sviluppo. Inoltre, l’intelligenza artificiale non deve sostituire il ruolo umano, ma piuttosto amplificare le capacità dei professionisti, garantendo che la responsabilità finale resti nelle loro mani.
 Rimani sempre aggiornato, seguici su Google News!
Seguici
Rimani sempre aggiornato, seguici su Google News!
Seguici
Notizie correlate
Speciali Tutti gli speciali
Calendario Tutto
G11 Media Networks
SecurityOpenLab e' un canale di BitCity, testata giornalistica registrata presso il tribunale di Como ,
n. 21/2007 del
11/10/2007- Iscrizione ROC n. 15698
G11 MEDIA S.R.L.
Sede Legale Via NUOVA VALASSINA, 4 22046 MERONE (CO) - P.IVA/C.F.03062910132
Registro imprese di Como n. 03062910132 - REA n. 293834 CAPITALE SOCIALE Euro 30.000 i.v.
