
Agenti AI auto-apprendenti per la sicurezza del codice AI
Agenti AI collaborativi analizzano, testano e correggono vulnerabilità nel codice generato dagli LLM, riducendo i rischi della programmazione automatica.



La sicurezza dell’intelligenza artificiale è uno dei temi portanti che stiamo affrontando su SecurityOpenLab, consapevoli che la diffusione dell’AI sta ridefinendo il perimetro delle minacce e delle strategie difensive. Da tempo il nostro sito approfondisce le declinazioni più avanzate della cybersecurity applicata all’AI, come l’apprendimento contrastivo (una strategia promettente contro il malware sviluppata proprio da CrowdStrike), la rapida evoluzione delle tecniche di attacco agli LLM con le nuove metodologie di jailbreak automatizzato, le minacce legate alla manipolazione dei prompt, finanche alle sofisticate strategie di deceptive delight che mettono a dura prova anche i sistemi più avanzati.
In questo scenario si inserisce una seconda ricerca presentata da CrowdStrike, relativa all’impiego di agenti AI auto-apprendenti per proteggere il codice generato automaticamente. Rappresenta una tappa fondamentale della difesa cyber e conferma quanto l’innovazione nel campo della cybersecurity sia ormai indissolubilmente legata all’evoluzione dell’AI. In particolare, il riferimento è al cosiddetto vibe coding - l’approccio con il quale il programmatore descrive all’LLM in linguaggio naturale ciò che desidera ottenere, senza preoccuparsi dei dettagli tecnici o della sintassi, delegando quasi completamente la scrittura del codice all’AI.
Questa democratizzazione dello sviluppo riduce le barriere d’accesso alla programmazione, ma introduce un rischio: la rapidità con cui il codice viene generato supera la capacità umana di revisione, in un contesto in cui la complessità degli algoritmi rende difficile individuare errori, vulnerabilità o comportamenti indesiderati prima che il software venga messo in produzione. La proposta di CrowdStrike di utilizzare sistemi multi-agente autoapprendenti per la protezione del codice generato dall’AI si rivela pertanto interessante.
Un contesto complicato
I problemi che legano la cybersecurity e la programmazione sono molteplici e intrecciate: basti ricordare il caso SolarWinds per comprendere le ripercussioni pratiche. Quando il codice viene prodotto da un LLM, il rischio che contenga vulnerabilità note o sconosciute aumenta esponenzialmente proprio perché la velocità e la quantità di output superano di gran lunga la capacità di controllo manuale. Gli errori possono spaziare dall’inclusione involontaria di backdoor all’uso di librerie non sicure, fino a logiche di autenticazione deboli o a errori di validazione degli input che aprono la strada a exploit di vario genere. Le conseguenze in questi casi vanno dalla compromissione dei dati sensibili alla diffusione di malware, fino all’escalation di privilegi che permette agli attaccanti di prendere il controllo dei sistemi. In più, come abbiamo documentato su SecurityOpenLab, la manipolazione degli LLM tramite jailbreak o prompt injection può indurre i modelli a generare codice dannoso o a bypassare i controlli di sicurezza implementati, aggravando ulteriormente il quadro delle minacce.

Per affrontare questa nuova complessità, CrowdStrike ha sviluppato un sistema di agenti AI autoapprendenti in grado di collaborare tra loro per identificare, testare e correggere le vulnerabilità nel codice prodotto dagli LLM. Quello che descrivono sul blog ufficiale gli esperti di CrowdStrike Research è un approccio basato su una catena di automazione intelligente che riproduce, in chiave digitale e scalabile, le migliori pratiche della security applicativa, dalla revisione del codice alla simulazione degli attacchi, fino alla generazione automatica di patch e test di validazione.
La protezione del codice generato dall’AI
In sintesi, il sistema integra tre agenti specializzati che operano in sinergia. Il primo si occupa di analizzare il codice sorgente alla ricerca di vulnerabilità, sfruttando tecniche avanzate di Static Application Security Testing (SAST) potenziate da modelli di machine learning addestrati su milioni di esempi di codice sicuro e vulnerabile. Questo agente non si limita a individuare pattern noti, ma apprende continuamente dai nuovi casi che incontra, migliorando la propria capacità di riconoscere anche le minacce emergenti.
Una volta individuata una possibile falla, entra in gioco il secondo agente, che simula il comportamento di un attaccante. Questo agente di red teaming sviluppa exploit specifici per testare la reale possibilità di sfruttare la falla rilevata, utilizzando una base di conoscenze aggiornata sulle tecniche di attacco più recenti, comprese quelle legate ai jailbreak degli LLM e alle manipolazioni dei prompt che abbiamo raccontato negli articoli precedenti di SecurityOpenLab. Se l’exploit risulta efficace, il sistema passa alla fase successiva, affidata al terzo agente: quello dedicato alla correzione automatica. Qui, l’intelligenza artificiale genera patch mirate per chiudere la vulnerabilità e produce unit test per verificarne l’efficacia, assicurandosi che la correzione non introduca nuovi problemi o comprometta la funzionalità originale del codice.
La vera innovazione di questo modello risiede nella capacità degli agenti di apprendere e migliorare costantemente attraverso un processo di reinforcement learning collaborativo. Ciascun agente condivide i risultati e i feedback con gli altri, creando un ciclo virtuoso in cui le strategie di rilevamento, attacco e difesa si affinano progressivamente. Per esempio, l’agente di red teaming può perfezionare le proprie tecniche di exploitation analizzando le patch sviluppate in precedenza, mentre quello di scansione aggiorna i propri modelli sulla base degli exploit che hanno avuto successo o meno. L’approccio, ispirato a quanto già sperimentato da CrowdStrike con architetture neurali specializzate come MalConv2 per l’analisi dei file PE, consente di trasformare il codice in rappresentazioni vettoriali ottimizzate per la detection di pattern malevoli, aumentando la precisione e la velocità dell’intero processo.
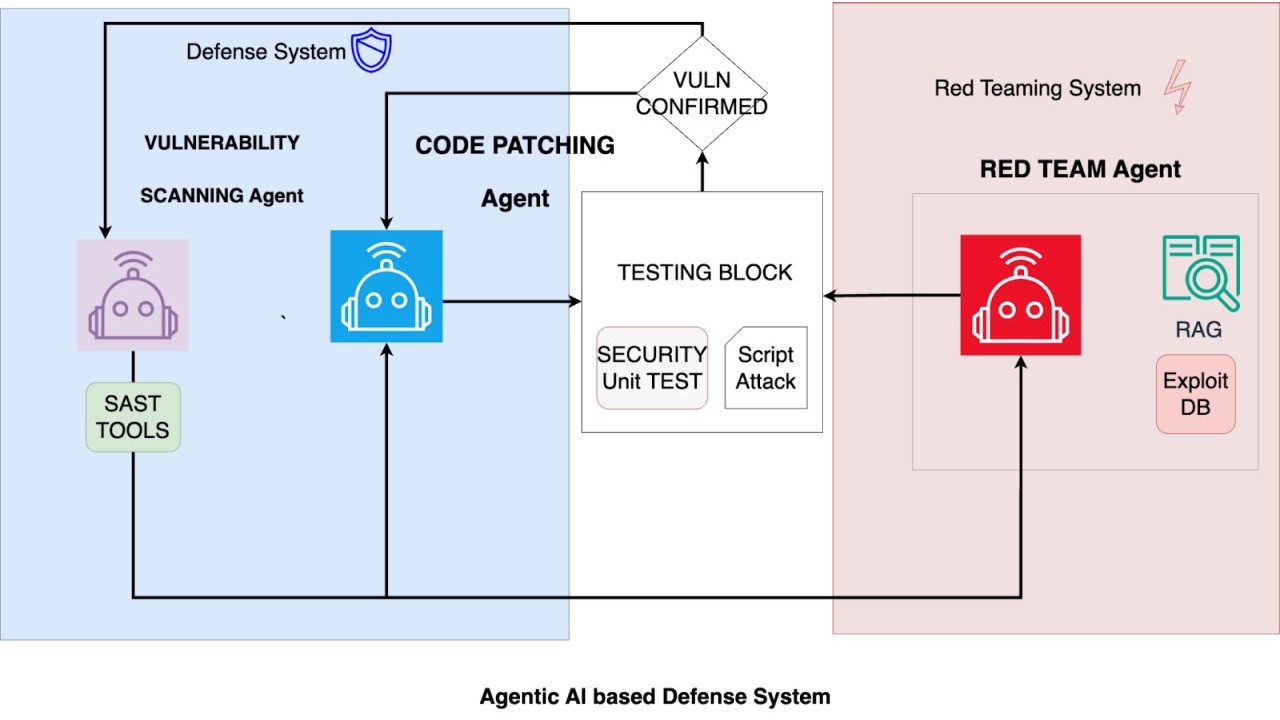 I tre agenti di intelligenza artificiale che lavorano insieme
I tre agenti di intelligenza artificiale che lavorano insieme
I test
Nella fase di validazione il sistema è stato testato su un dataset di oltre 15 milioni di campioni di codice che includevano sia applicazioni legittime che malware. I risultati sono stati significativi: il tempo medio necessario per individuare e correggere una vulnerabilità si è ridotto del 68% rispetto ai metodi tradizionali, dimostrando come l’automazione intelligente possa colmare il gap tra la rapidità dello sviluppo AI-driven e la necessità di garantire la sicurezza del software. Il dato è particolarmente rilevante se si considera che, nel contesto attuale, la maggior parte delle vulnerabilità viene scoperta solo dopo la diffusione del software, quando i danni potenziali sono già elevati e le attività di remediation risultano più costose e complesse.
L’integrazione di agenti AI autoapprendenti nel ciclo di vita dello sviluppo software si propone pertanto come una possibile risposta concreta e scalabile alla sfida posta dall’automazione della programmazione. Vale la pena chiarire che non rimpiazza l’intervento umano, bensì lo potenzia permettendo agli sviluppatori di concentrarsi su aspetti più creativi e strategici. Allo stesso tempo, questa strategia promette di alzare il livello di sicurezza delle applicazioni, riducendo il rischio che vulnerabilità note o sconosciute vengano sfruttate da attaccanti sofisticati, come quelli che utilizzano le tecniche di jailbreak automatizzato e di prompt injection che abbiamo descritto nei nostri approfondimenti.
Guardando al futuro, è evidente che la sicurezza del codice generato dall’AI sarà sempre più centrale nella definizione delle strategie di difesa delle organizzazioni. La ricerca di CrowdStrike suggerisce che la chiave per affrontare questa sfida sia da ricercare nella capacità di integrare l’AI sia come strumento di sviluppo, sia come alleato nella protezione del software. L’esperienza maturata nell’applicazione dell’apprendimento contrastivo contro il malware, unita alla comprensione delle nuove minacce legate agli LLM, conferma che l’innovazione tecnologica deve andare di pari passo con l’evoluzione delle strategie di sicurezza per consentire lo sfruttamento dell’AI senza l’esposizione al rischio di dati, sistemi e persone.
 Rimani sempre aggiornato, seguici su Google News!
Seguici
Rimani sempre aggiornato, seguici su Google News!
Seguici
Notizie correlate
Speciali Tutti gli speciali
Calendario Tutto
G11 Media Networks
SecurityOpenLab e' un canale di BitCity, testata giornalistica registrata presso il tribunale di Como ,
n. 21/2007 del
11/10/2007- Iscrizione ROC n. 15698
G11 MEDIA S.R.L.
Sede Legale Via NUOVA VALASSINA, 4 22046 MERONE (CO) - P.IVA/C.F.03062910132
Registro imprese di Como n. 03062910132 - REA n. 293834 CAPITALE SOCIALE Euro 30.000 i.v.
